step_nearmiss() creates a specification of a recipe step that removes
majority class instances by undersampling points in the majority class based
on their distance to points in the minority class.
Usage
step_nearmiss(
recipe,
...,
role = NA,
trained = FALSE,
column = NULL,
under_ratio = 1,
neighbors = 5,
distance = "euclidean",
version = 1,
n_neighbors_ver3 = 3,
skip = TRUE,
seed = sample.int(10^5, 1),
distance_with = recipes::all_predictors(),
id = rand_id("nearmiss")
)Arguments
- recipe
A recipe object. The step will be added to the sequence of operations for this recipe.
- ...
One or more selector functions to choose which variable is used to sample the data. See recipes::selections for more details. The selection should result in single factor variable. For the
tidymethod, these are not currently used.- role
Not used by this step since no new variables are created.
- trained
A logical to indicate if the quantities for preprocessing have been estimated.
- column
A character string of the variable name that will be populated (eventually) by the
...selectors.- under_ratio
A numeric value for the ratio of the majority-to-minority frequencies. The default value (1) means that all other levels are sampled down to have the same frequency as the least occurring level. A value of 2 would mean that the majority levels will have (at most) (approximately) twice as many rows than the minority level.
A named numeric vector can be used instead to give different levels different targets, for example
c(a = 2, b = 3). The names must be levels of the outcome and the values are ratios of the minority level, exactly as in the single-number case. Levels that are not named are left untouched, as are rows with a missing outcome. Because a vector of targets is not a single value, supplying one means this argument can no longer be tuned. Seevignette("ratio", package = "themis")for more details.- neighbors
An integer. Number of nearest neighbor that are used to generate the new examples of the minority class.
- distance
A character string specifying the distance metric used for nearest neighbor calculations, defaulting to
"euclidean". The available metrics fall into three groups."euclidean","cosine", and"mahalanobis"use approximate nearest neighbors via the RANN package and scale well to large datasets."squared_chord","matusita","hellinger", and"bhattacharyya"are probability-divergence measures that treat each row as a distribution over the predictors, so they require non-negative values."hellinger"and"bhattacharyya"further require each row to sum to 1. All four also use the RANN package and scale well to large datasets."manhattan","chebyshev","canberra","soergel","lorentzian","jeffreys","topsoe","jensen-shannon","jensen_difference","taneja", and"kumar-johnson"compute an exact all-pairs distance matrix. This takes time and memory proportional to the square of the number of observations in a class, so these are best suited to smaller datasets. Everything from"canberra"onwards is a probability divergence requiring non-negative values, is provided by the philentropy package (which must be installed separately), and in the case of"jeffreys","taneja", and"kumar-johnson"requires strictly positive values, since those divide by individual predictor values.The probability divergences are meaningful for compositional predictors such as proportions or counts normalized per observation, and are generally not appropriate for standardized predictors.
- version
An integer. Which of the three NearMiss variants to use,
1,2, or3. Defaults to1. See the details section.- n_neighbors_ver3
An integer. The number of nearest neighbors used to build the candidate pool of the NearMiss-3 variant. Only used when
version = 3. Defaults to3.- skip
A logical. Should the step be skipped when the recipe is baked by
bake()? While all operations are baked whenprep()is run, some operations may not be able to be conducted on new data (e.g. processing the outcome variable(s)). Care should be taken when usingskip = TRUEas it may affect the computations for subsequent operations.- seed
An integer that will be used as the seed when applied.
- distance_with
A call to a selector function to choose which variables are used for distance calculations. Defaults to
recipes::all_predictors(). The variable selected by...is always excluded from the distance calculations.- id
A character string that is unique to this step to identify it.
Value
An updated version of recipe with the new step
added to the sequence of existing steps (if any). For the
tidy method, a tibble with columns terms which is
the variable used to sample.
Details
The version argument selects between the three NearMiss variants:
version = 1Retains the points from the majority class which have the smallest mean distance to their nearest points in the minority class.
version = 2Retains the points from the majority class which have the smallest mean distance to their farthest points in the minority class.
version = 3Works in two stages. First, the
n_neighbors_ver3nearest majority class neighbors of each minority class point form a candidate pool, and all other majority class points are removed. Then the points of that pool which have the largest mean distance to their nearest minority class points are retained.
Since the size of the NearMiss-3 candidate pool is governed by
n_neighbors_ver3 rather than by under_ratio, the pool can be smaller
than the target set by under_ratio. The whole pool is then retained and
the target is not reached.
With more than two classes, the mean distance is computed to the nearest points across all other classes, not only the minority class. This differs from imbalanced-learn, which measures distance to the minority class only. The binary case, the primary intended use, is unaffected.
All columns in the data are sampled and returned by recipes::juice()
and recipes::bake().
All columns selected by distance_with must be numeric with no missing
data.
When used in modeling, users should strongly consider using the
option skip = TRUE so that the extra sampling is not
conducted outside of the training set.
Minimum observations
Each minority class must have at least neighbors + 1 observations to
perform the NearMiss algorithm.
Tidying
When you tidy() this step, a tibble is returned with
columns terms and id:
- terms
character, the selectors or variables selected
- id
character, id of this step
Tuning Parameters
This step has 2 tuning parameters:
under_ratio: Under-Sampling Ratio (type: double, default: 1)neighbors: # Nearest Neighbors (type: integer, default: 5)
Case weights
The underlying operation does not allow for case weights. Supplying data with a case weights column to this step results in an error.
References
Inderjeet Mani and I Zhang. knn approach to unbalanced data distributions: a case study involving information extraction. In Proceedings of workshop on learning from imbalanced datasets, 2003.
See also
nearmiss() for direct implementation
Other Steps for under-sampling:
step_cluster_centroids(),
step_cnn(),
step_downsample(),
step_enn(),
step_instance_hardness(),
step_ncl(),
step_oss(),
step_tomek()
Examples
library(recipes)
library(modeldata)
data(hpc_data)
hpc_data0 <- hpc_data |>
select(-protocol, -day)
orig <- count(hpc_data0, class, name = "orig")
orig
#> # A tibble: 4 × 2
#> class orig
#> <fct> <int>
#> 1 VF 2211
#> 2 F 1347
#> 3 M 514
#> 4 L 259
up_rec <- recipe(class ~ ., data = hpc_data0) |>
# Bring the majority levels down to about 1000 each
# 1000/259 is approx 3.862
step_nearmiss(class, under_ratio = 3.862) |>
prep()
training <- up_rec |>
bake(new_data = NULL) |>
count(class, name = "training")
training
#> # A tibble: 4 × 2
#> class training
#> <fct> <int>
#> 1 VF 1000
#> 2 F 1000
#> 3 M 514
#> 4 L 259
# Since `skip` defaults to TRUE, baking the step has no effect
baked <- up_rec |>
bake(new_data = hpc_data0) |>
count(class, name = "baked")
baked
#> # A tibble: 4 × 2
#> class baked
#> <fct> <int>
#> 1 VF 2211
#> 2 F 1347
#> 3 M 514
#> 4 L 259
# Note that if the original data contained fewer rows than the
# target n (= ratio * minority_n), the data are left alone:
orig |>
left_join(training, by = "class") |>
left_join(baked, by = "class")
#> # A tibble: 4 × 4
#> class orig training baked
#> <fct> <int> <int> <int>
#> 1 VF 2211 1000 2211
#> 2 F 1347 1000 1347
#> 3 M 514 514 514
#> 4 L 259 259 259
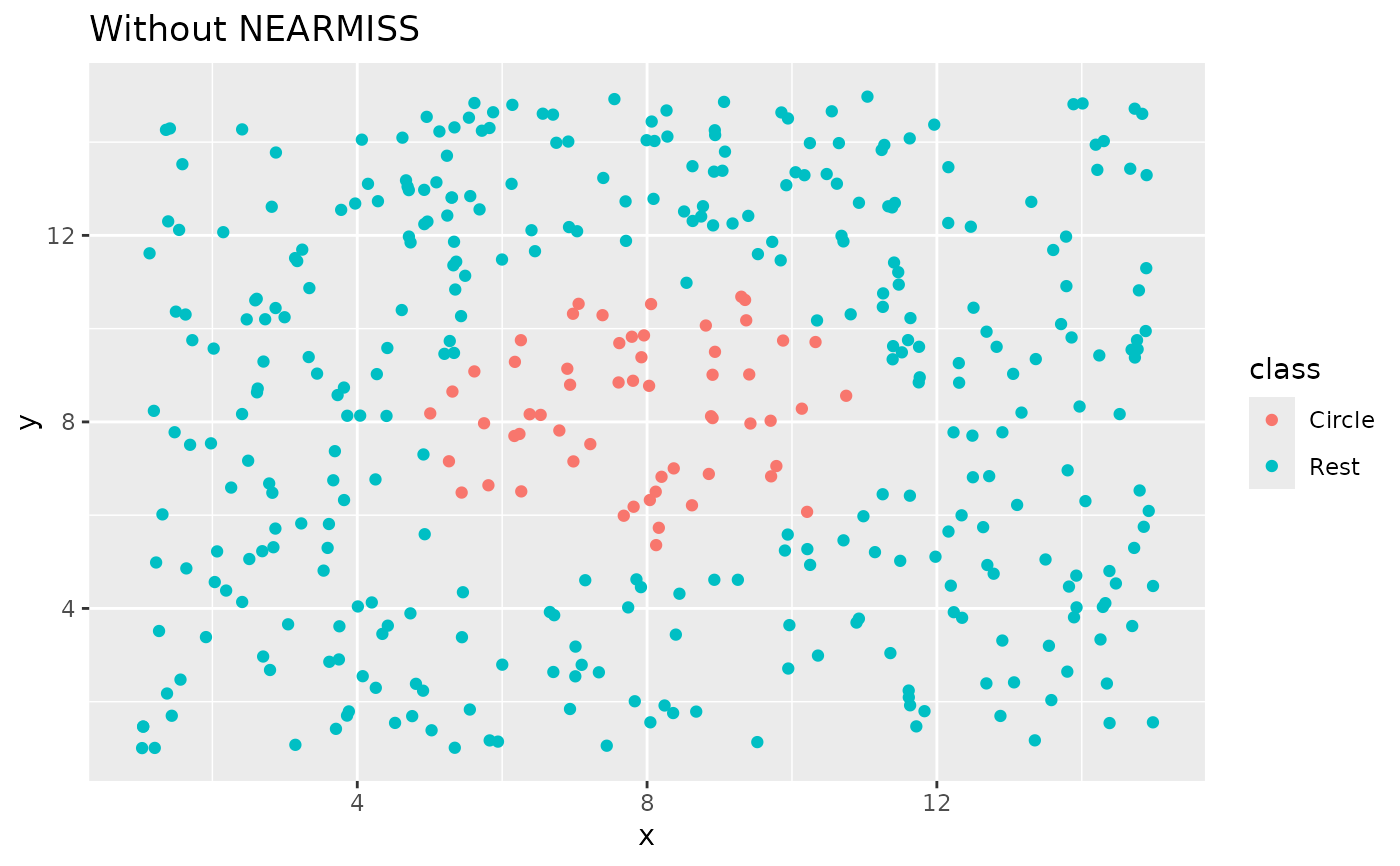
library(ggplot2)
ggplot(circle_example, aes(x, y, color = class)) +
geom_point() +
labs(title = "Without NEARMISS") +
xlim(c(1, 15)) +
ylim(c(1, 15))
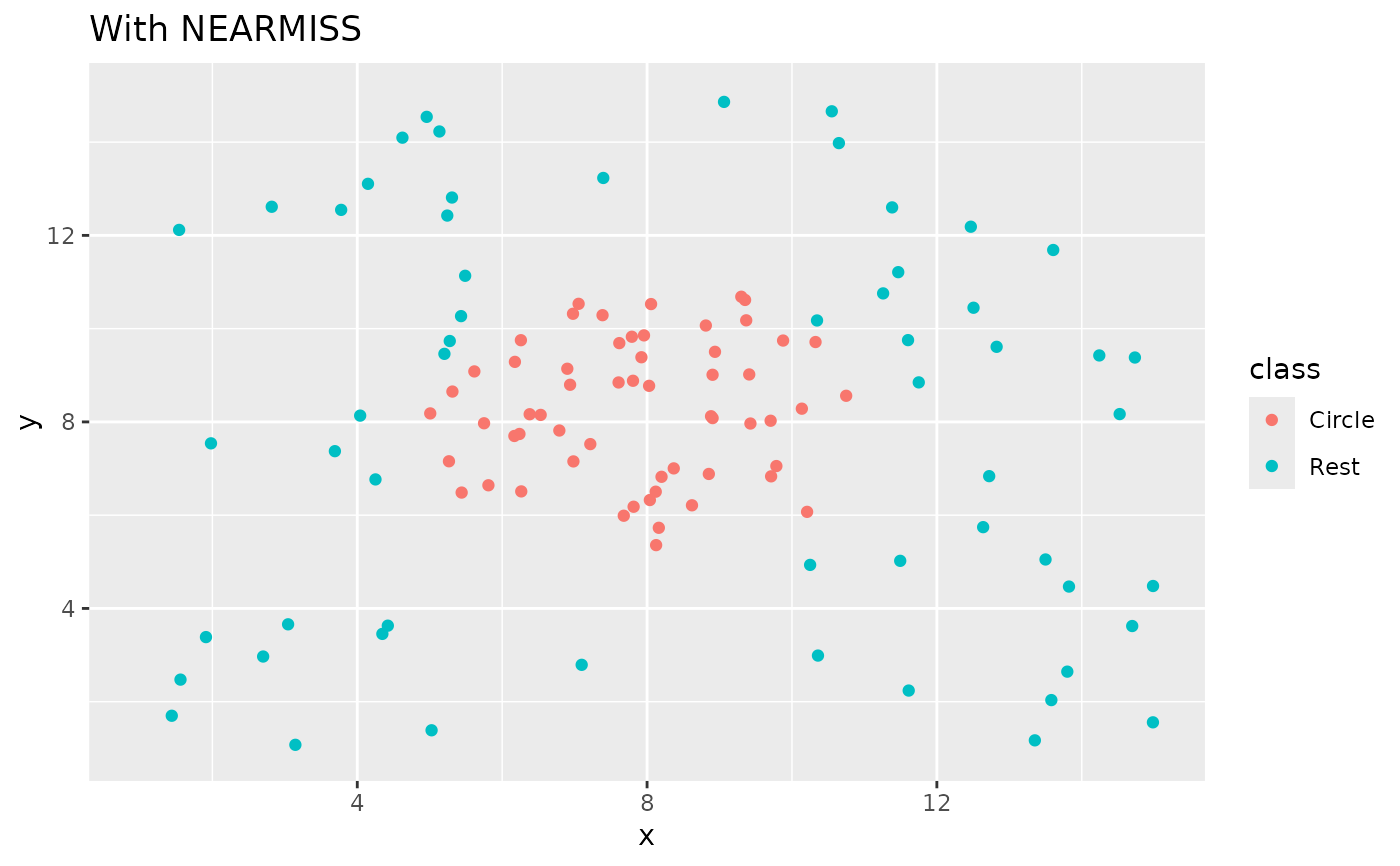
 recipe(class ~ x + y, data = circle_example) |>
step_nearmiss(class) |>
prep() |>
bake(new_data = NULL) |>
ggplot(aes(x, y, color = class)) +
geom_point() +
labs(title = "With NEARMISS") +
xlim(c(1, 15)) +
ylim(c(1, 15))
recipe(class ~ x + y, data = circle_example) |>
step_nearmiss(class) |>
prep() |>
bake(new_data = NULL) |>
ggplot(aes(x, y, color = class)) +
geom_point() +
labs(title = "With NEARMISS") +
xlim(c(1, 15)) +
ylim(c(1, 15))