step_nearmiss() creates a specification of a recipe step that removes
majority class instances by undersampling points in the majority class based
on their distance to other points in the same class.
Usage
step_nearmiss(
recipe,
...,
role = NA,
trained = FALSE,
column = NULL,
under_ratio = 1,
neighbors = 5,
skip = TRUE,
seed = sample.int(10^5, 1),
id = rand_id("nearmiss")
)Arguments
- recipe
A recipe object. The step will be added to the sequence of operations for this recipe.
- ...
One or more selector functions to choose which variable is used to sample the data. See recipes::selections for more details. The selection should result in single factor variable. For the
tidymethod, these are not currently used.- role
Not used by this step since no new variables are created.
- trained
A logical to indicate if the quantities for preprocessing have been estimated.
- column
A character string of the variable name that will be populated (eventually) by the
...selectors.- under_ratio
A numeric value for the ratio of the majority-to-minority frequencies. The default value (1) means that all other levels are sampled down to have the same frequency as the least occurring level. A value of 2 would mean that the majority levels will have (at most) (approximately) twice as many rows than the minority level.
- neighbors
An integer. Number of nearest neighbor that are used to generate the new examples of the minority class.
- skip
A logical. Should the step be skipped when the recipe is baked by
bake()? While all operations are baked whenprep()is run, some operations may not be able to be conducted on new data (e.g. processing the outcome variable(s)). Care should be taken when usingskip = TRUEas it may affect the computations for subsequent operations.- seed
An integer that will be used as the seed when applied.
- id
A character string that is unique to this step to identify it.
Value
An updated version of recipe with the new step
added to the sequence of existing steps (if any). For the
tidy method, a tibble with columns terms which is
the variable used to sample.
Details
This method retains the points from the majority class which have the smallest mean distance to the k nearest points in the minority class.
All columns in the data are sampled and returned by recipes::juice()
and recipes::bake().
All columns used in this step must be numeric with no missing data.
When used in modeling, users should strongly consider using the
option skip = TRUE so that the extra sampling is not
conducted outside of the training set.
Tidying
When you tidy() this step, a tibble is retruned with
columns terms and id:
- terms
character, the selectors or variables selected
- id
character, id of this step
Tuning Parameters
This step has 2 tuning parameters:
under_ratio: Under-Sampling Ratio (type: double, default: 1)neighbors: # Nearest Neighbors (type: integer, default: 5)
References
Inderjeet Mani and I Zhang. knn approach to unbalanced data distributions: a case study involving information extraction. In Proceedings of workshop on learning from imbalanced datasets, 2003.
See also
nearmiss() for direct implementation
Other Steps for under-sampling:
step_downsample(),
step_tomek()
Examples
library(recipes)
library(modeldata)
data(hpc_data)
hpc_data0 <- hpc_data %>%
select(-protocol, -day)
orig <- count(hpc_data0, class, name = "orig")
orig
#> # A tibble: 4 × 2
#> class orig
#> <fct> <int>
#> 1 VF 2211
#> 2 F 1347
#> 3 M 514
#> 4 L 259
up_rec <- recipe(class ~ ., data = hpc_data0) %>%
# Bring the majority levels down to about 1000 each
# 1000/259 is approx 3.862
step_nearmiss(class, under_ratio = 3.862) %>%
prep()
training <- up_rec %>%
bake(new_data = NULL) %>%
count(class, name = "training")
training
#> # A tibble: 4 × 2
#> class training
#> <fct> <int>
#> 1 VF 1000
#> 2 F 1000
#> 3 M 514
#> 4 L 259
# Since `skip` defaults to TRUE, baking the step has no effect
baked <- up_rec %>%
bake(new_data = hpc_data0) %>%
count(class, name = "baked")
baked
#> # A tibble: 4 × 2
#> class baked
#> <fct> <int>
#> 1 VF 2211
#> 2 F 1347
#> 3 M 514
#> 4 L 259
# Note that if the original data contained more rows than the
# target n (= ratio * majority_n), the data are left alone:
orig %>%
left_join(training, by = "class") %>%
left_join(baked, by = "class")
#> # A tibble: 4 × 4
#> class orig training baked
#> <fct> <int> <int> <int>
#> 1 VF 2211 1000 2211
#> 2 F 1347 1000 1347
#> 3 M 514 514 514
#> 4 L 259 259 259
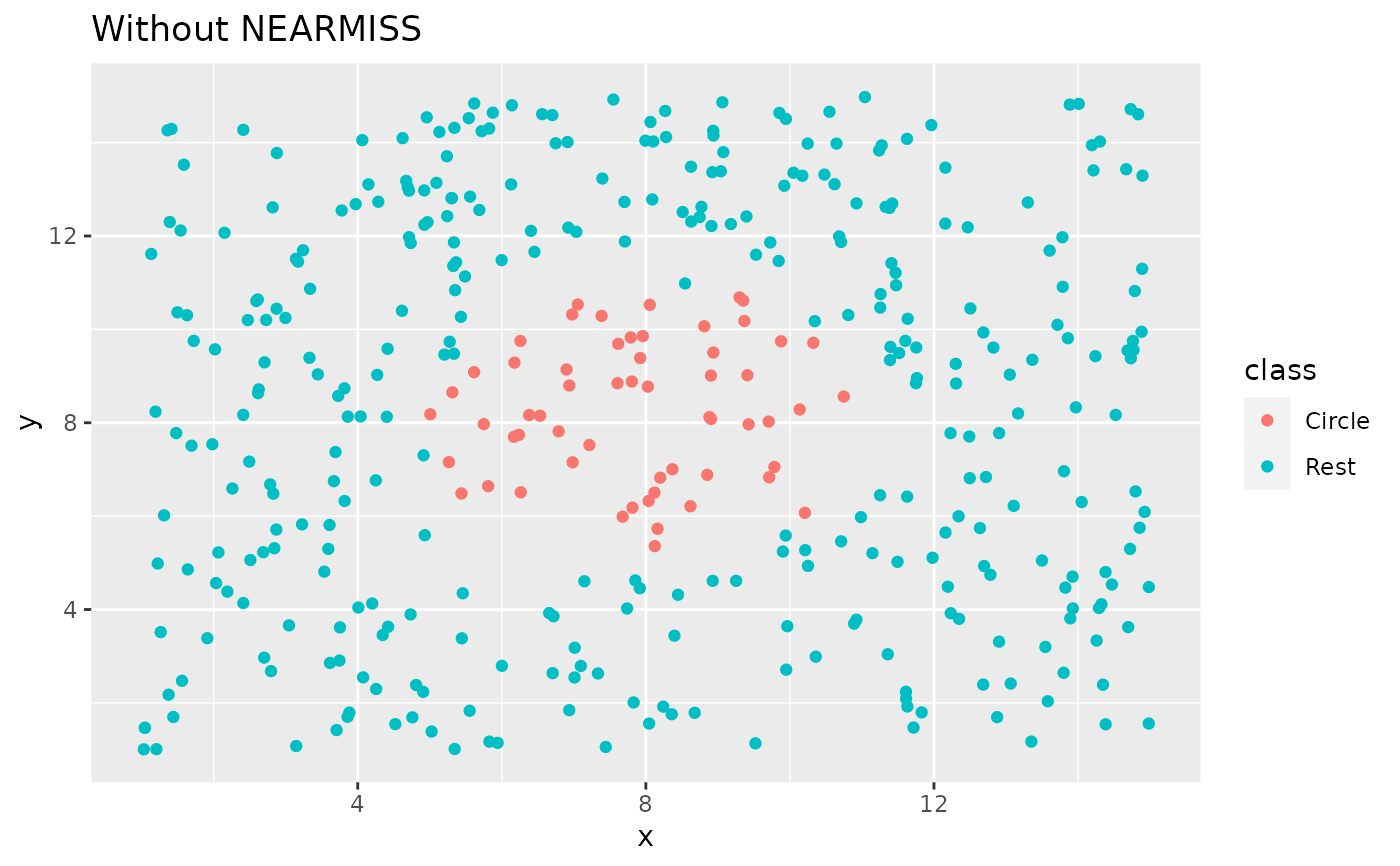
library(ggplot2)
ggplot(circle_example, aes(x, y, color = class)) +
geom_point() +
labs(title = "Without NEARMISS") +
xlim(c(1, 15)) +
ylim(c(1, 15))
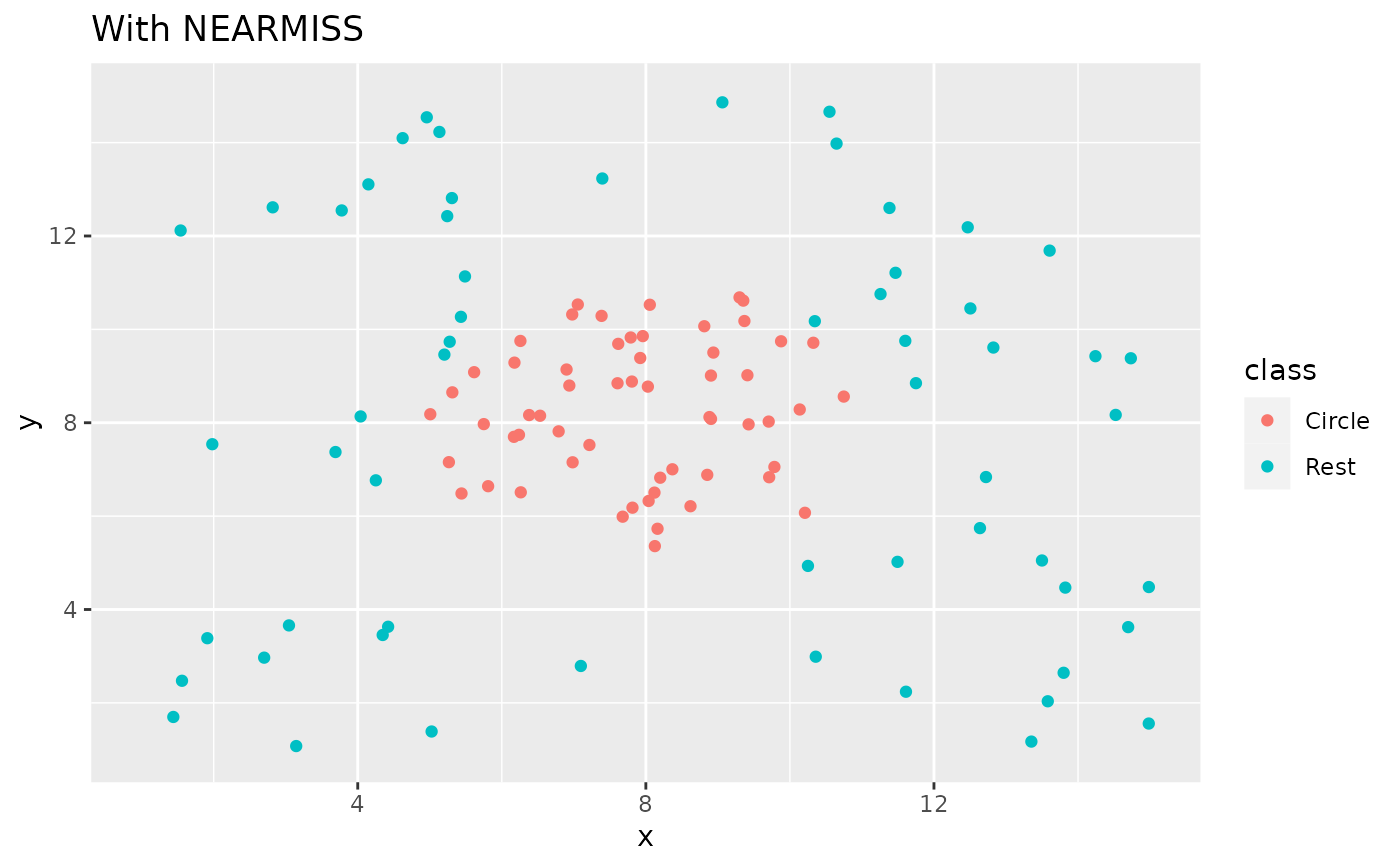
 recipe(class ~ x + y, data = circle_example) %>%
step_nearmiss(class) %>%
prep() %>%
bake(new_data = NULL) %>%
ggplot(aes(x, y, color = class)) +
geom_point() +
labs(title = "With NEARMISS") +
xlim(c(1, 15)) +
ylim(c(1, 15))
recipe(class ~ x + y, data = circle_example) %>%
step_nearmiss(class) %>%
prep() %>%
bake(new_data = NULL) %>%
ggplot(aes(x, y, color = class)) +
geom_point() +
labs(title = "With NEARMISS") +
xlim(c(1, 15)) +
ylim(c(1, 15))